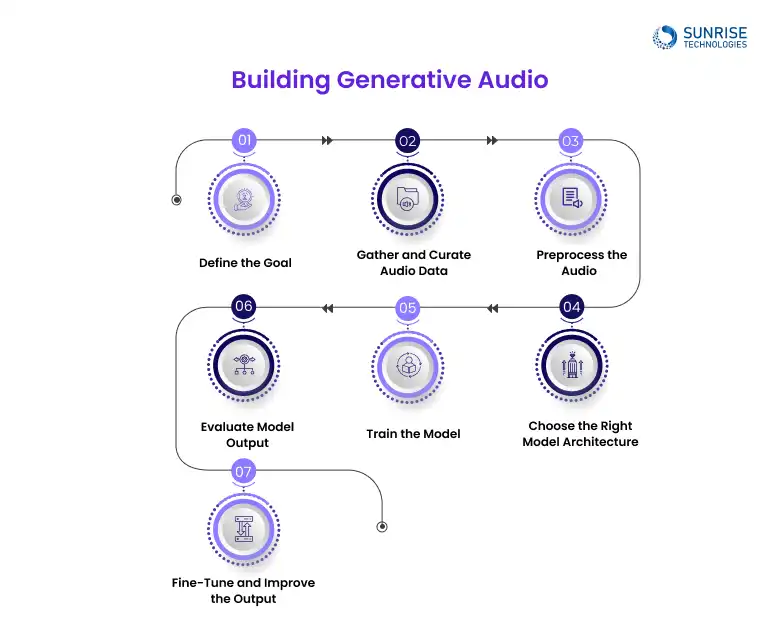

To create a generative audio model with deep learning, you’ll need a large dataset of audio, preprocess it into a format suitable for training (such as spectrograms), choose a model like GANs or RNNs, and train it using a machine learning framework. Explore our Generative AI Development Services to learn more or get in touch with our experts today.
The development cost of a generative audio model varies based on the complexity, training data volume, and the choice of AI model (e.g., WaveNet, Jukebox, or DiffWave). On average:
- Basic prototype (using open-source models + minimal tuning): $10,000–$25,000
- Custom-trained mid-range model (with dataset collection & tuning): $30,000–$75,000
- Enterprise-level model (custom datasets, multi-language support, real-time synthesis): $100,000+
AI voice synthesis uses neural networks for sound to replicate human speech patterns by training on voice data. These models can generate realistic human voices for virtual assistants and other applications.
You can use machine learning for audio synthesis by training generative audio models on large audio datasets, leveraging architectures like RNNs or GANs to generate realistic audio content like music or speech.
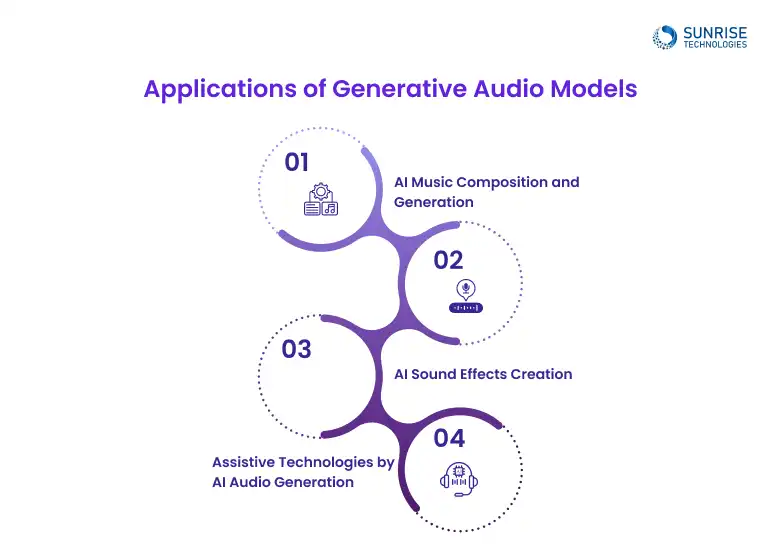
The future of generative audio models is focused on improving the realism and creativity of AI-generated content, with applications in music, voice synthesis, and sound design continuing to grow across industries.