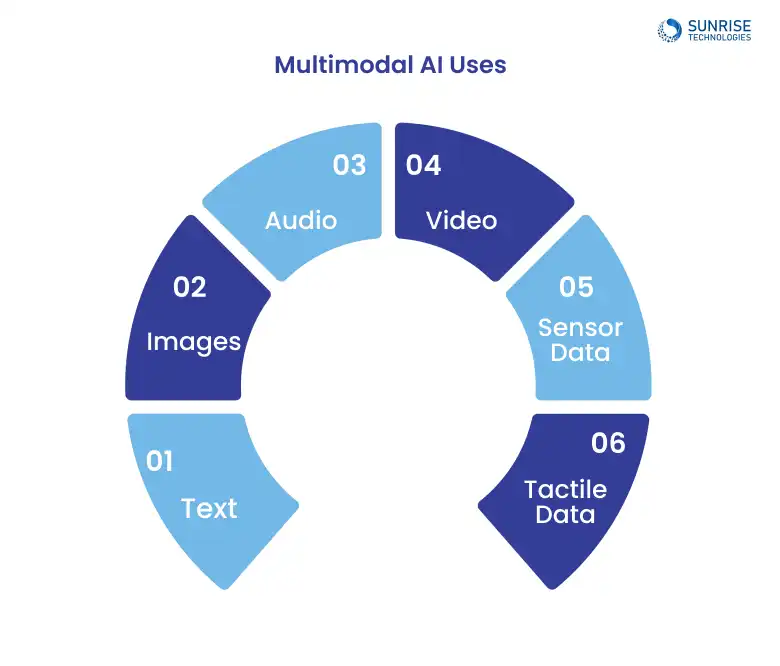


From healthcare diagnostics to retail shopping assistants and smart surveillance, real-world applications of multimodal AI in business are vast and growing daily.
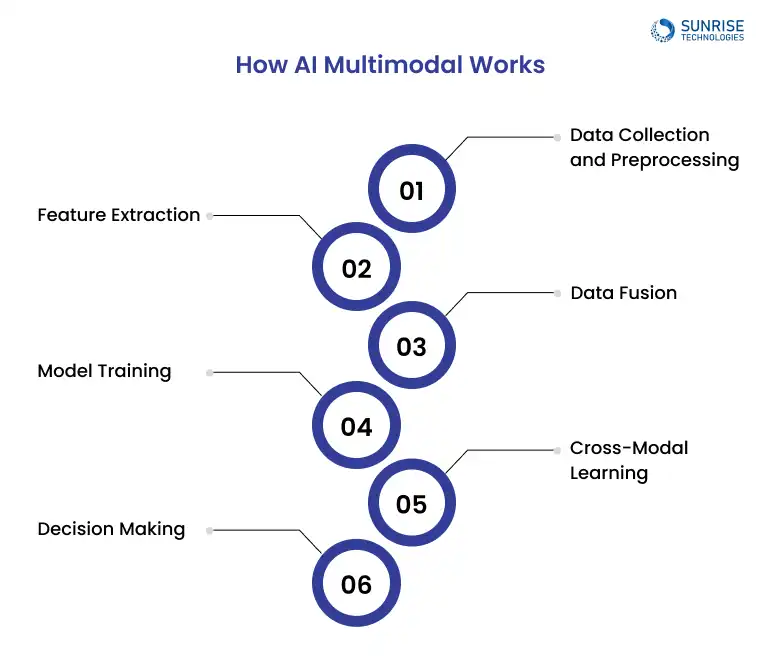
By aligning features across different data types, multimodal AI improves cross-modal learning, enabling the system to draw relationships between speech, image, and other inputs for more accurate predictions.
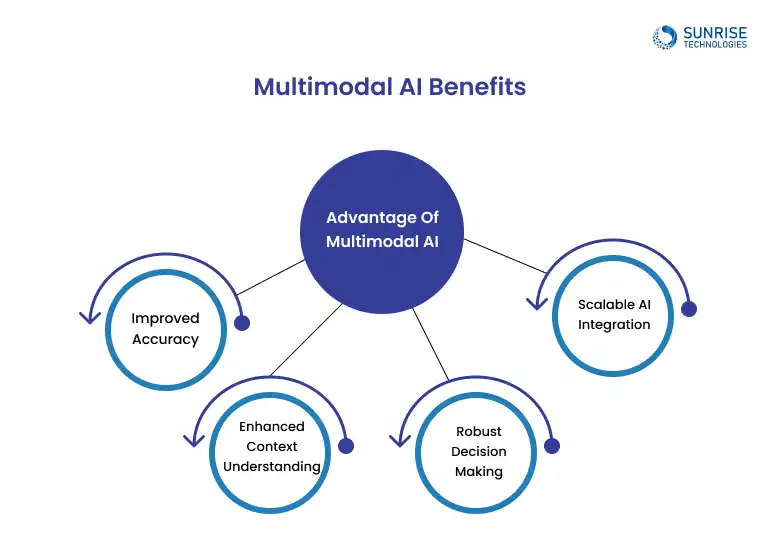
Multimodal AI enhances context understanding, reduces bias, and ensures robust decision-making through cross-modal learning and diverse data integration.
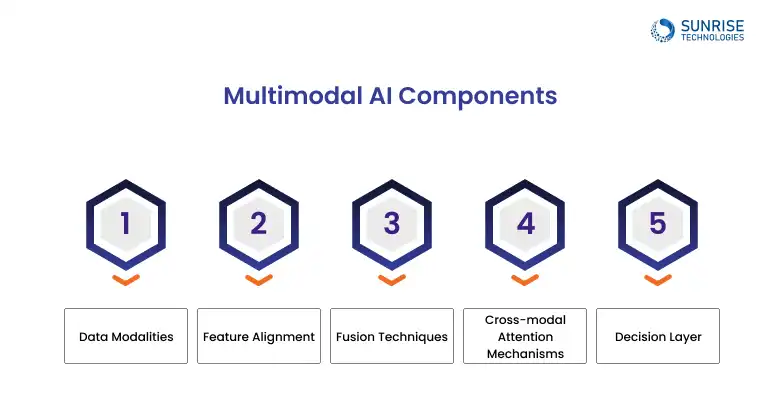
Natural language processing (NLP) and computer vision are core components in multimodal AI, allowing systems to understand both language and visuals contextually and simultaneously.
From improving diagnostics in healthcare to enhancing security in finance and customer engagement in retail, multimodal AI is transforming industries through widespread adoption and innovation.